Data Lake versus Data Warehouse
11/11/20, 9:10 am
A data warehouse doesn’t need any introduction to those belonging to the world of big data. But ever since the recent addition of a fresh aspect into the big data storage segment, data lakes, many organisations have been left puzzled and confused.
Whilst a data warehouse and data lake might sound similar, there are major differences to each approach. In this post, we highlight the key distinctions between the two as they both serve different purposes and require different sets of acumen to be effectively utilised.
Let’s begin with defining the two!
Data Warehouse
A data warehouse is a high-capacity repository system that typically stores only structured data from disparate sources. The data is processed and formatted for the purpose of comparison and analysis to gather business intelligence.
Data Lake
A data lake is a next-generation hybrid data repository solution. It is optimised for quick ingestion of structured, semi-structured and unstructured data from a wide variety of data sources, plus on-the-fly processing of such data for exploration, analytics and operations.
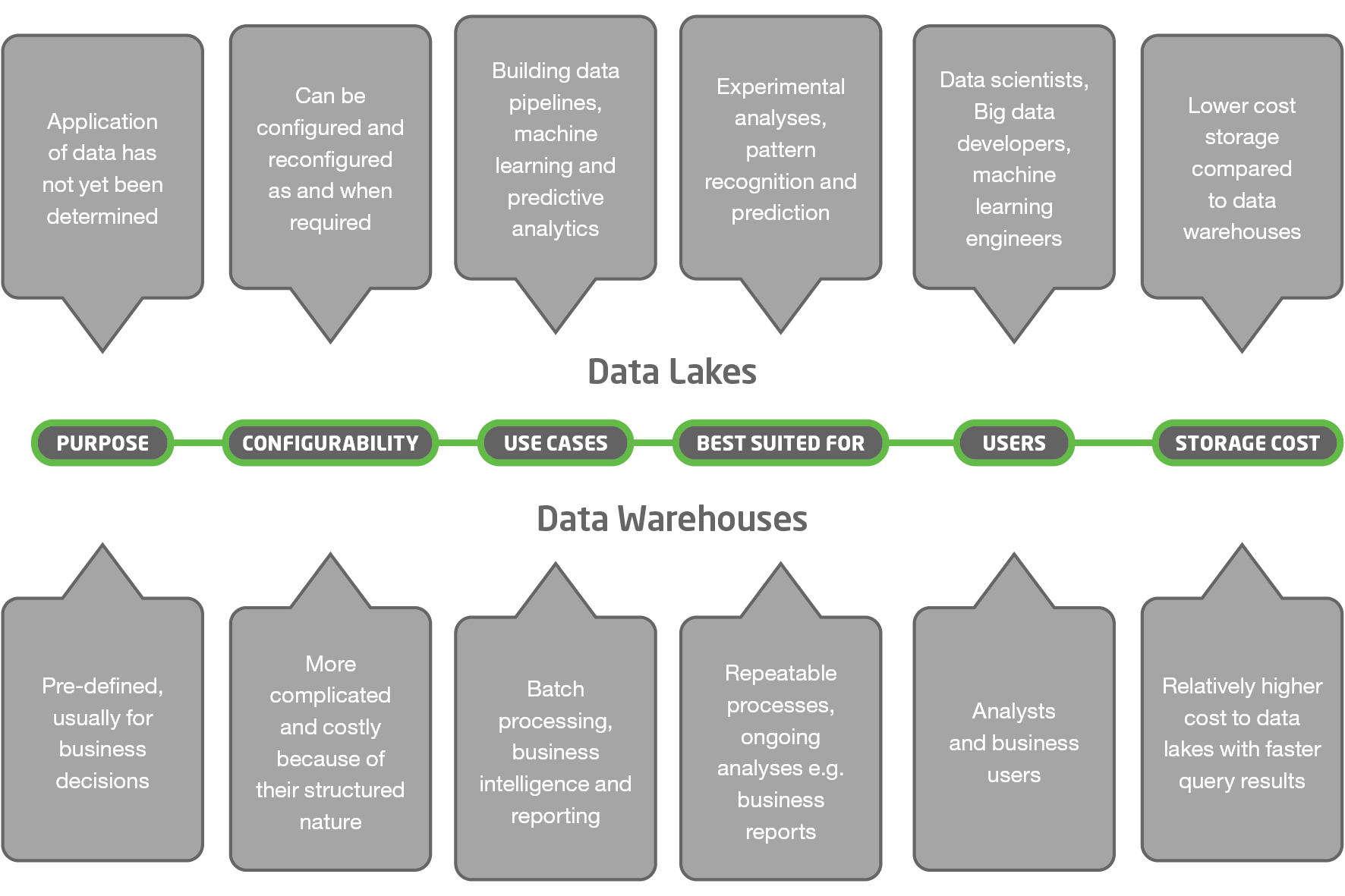
Key Differences between a Data Lake and Data Warehouse
Data Lake
The whole spectrum from raw (unprocessed, native format), unstructured to structured
Data Types
Data Warehouse
Structured, cleaned, curated and processed
Data Lake
Any source including text and images from social networks, measurements from IoT devices (e.g. light, heat, motion) and more structured data from ERP and CRM systems
Data Sources
Data Warehouse
Transactional systems (e.g. point-of-sale), operational databases (e.g. ERP systems) and applications with historical and relational structured data
Data Lake
Structure is developed when data is used
Data Processing
Data Warehouse
Data must have structure prior to use
Data Lake
Retained for an unlimited amount of time
Data Retention
Data Warehouse
Data is purged periodically; only stores data relevant to analysis
Differences in data use and application
Data Lake or Data Warehouse: What does your Business Need?
A data warehouse consolidates data from multiple databases in order to gain insights, archive structured data as well as for carrying out repeatable processes such as extracting month-on-month sales and to create website reports. It typically allows organisations to meet their day-to-day reporting needs as well as a good level of analysis.
According to projections from IDC, 80% of worldwide data will be unstructured by 2025. Unstructured data typically makes up around 70-80% of an organisation’s total data volume, including email, social media, blogs, videos content and others.
A data lake consolidates both structured and unstructured data from multiple sources and provides the ability to extend the analysis across a much larger data set. It allows organisations access to a larger set of data in order to do a more comprehensive analysis and gather deeper insights in order to react quickly when new business issues are identified, to discover patterns and trends and gain meaningful business insights.
Whether a business needs to utilise a data warehouse or a data lake depends on their goals. However, it is worth nothing that a significant chunk of an organisation's data is unstructured and without proper applications to utilise this data it limits the insights that an organisation can generate.

Raja Balakrishnan
National Solutions Manager
Raja.Balakrishnan@nec.com.au